· tutorials · 3 min read
Scraping Tags from Quotes - A Step-by-Step Guide
Welcome back to our series on writing automation scripts! In this episode, we're diving into web scraping, specifically targeting tags from a website dedicated to quotes. This guide will walk you through the process of extracting data and saving it into a CSV file, so you can use it for further analysis or integration into your applications.
This blog was generated from a tutorial video you can watch here
Understanding the Task
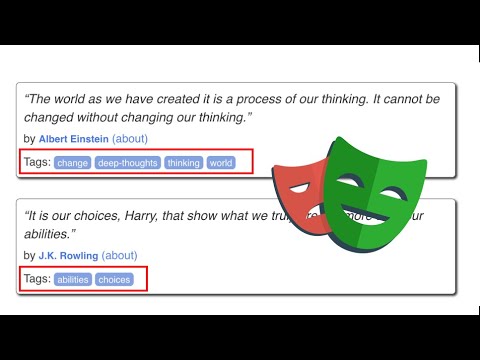
In today’s example, we will be scraping quotes along with their corresponding authors and tags from a dedicated webpage. The quotes, authors, and tags are the unique elements we want to focus on. To make this process smooth, we’ll leverage a script that’s been previously established, modifying it to suit our current needs.
Getting Started
First, we’ll open our automation tool (in this case, Automize) and select the relevant tag elements off the page. By double-clicking on a specific tag’s selector, we confirm that the automation tool correctly identifies multiple elements on the page—10 quotes in total.
Next, we’ll transition into our script setup. We start by ensuring our CSV writer is properly configured. Initially, our columns included title, price, and review, but we will adjust them to quote, author, and tags.
Here’s a snippet of what our setup will look like:
let quotes = await getQuotes(); // Function to fetch quotesLoops and Extraction
Now it’s time to loop through the quotes extracted from the page. For each quote, we need to collect text, author details, and associated tags. The loop structure will resemble:
for (let i = 0; i < quotes.length; i++) {
let quoteElement = quotes[i];
let text = quoteElement.querySelector('.itemprop-text').innerText;
let author = quoteElement.querySelector('.author').innerText;
}Within this loop, we fetch the text of the quote and the author’s name.
Handling Tags
Since quotes can have multiple tags, we need a secondary loop to handle them properly. This allows us to store all associated tags in an array, which we will later convert into a comma-separated string for our CSV output.
Here’s how the tag extraction looks:
let tags = [];
let tagElements = quoteElement.querySelectorAll('.tag');
tagElements.forEach(tag => {
tags.push(tag.innerText);
});Compiling Data
Following the loops for quotes and tags, we compile the data into an array of records that we will write to our CSV file. Each record will consist of the quote text, author, and the joined tags.
For example:
records.push({
quote: text,
author: author,
tags: tags.join(', ')
});Running the Script
Before executing the script, ensure you’ve addressed any potential errors in your code. For instance, ensure that all awaited functions are properly enclosed. Once everything is in place, running the script will open your browser, scrape the necessary elements, and then compile the data into a CSV file.
Upon completion, you’ll find a neatly organized list of quotes, their authors, and associated tags in your output file.
Conclusion
And there you have it! A straightforward approach to loop through webpage items and extract valuable information for your projects. This technique can be expanded or modified to scrape various types of data, so play around and see what you can accomplish.
Thank you for joining us in this episode! We hope you gained valuable insights into web scraping with automation scripts. Stay tuned for future episodes where we explore more automated solutions. Happy